A
brief introduction to the sensory backdriving model
If
I can do it justice with my own words...
The
basic theory is that when we recall mental imagery, we
activate many of the same neurons in primary visual cortex (V1) as
when we actually experienced those same images. It follows
then that since V1 fires as a direct topological map of what is being
seen in the real world (great pictures here
12), then visualized images projected from higher
cortex should also map out the same way in V1.
There
is a fair amount of experimental evidence
1-5 supporting this theory, but it is also intuitively
appealing. My two favorite reasons are:
Reason
1. At least as many axons run from higher processing regions of
our brains toward V1 as run from V1 to higher processing. What
is all this backtalk for? No mere camera gets this much feedback from
its television monitor.
A
simple explanation would be that the backtalk is doing a lot of
pattern completion 4
for the seeing and interpretation of the real world. But where does
pattern completion begin and imagination end? What about those times
when no real data at all is coming in and we still fill in the
gaps? We continue to visualize, and if the absence of sensory data is
absolute and long enough, the visualizations become hallucinatory and
indistinguishable from real sensory input. Pattern completion,
visualization, and seeing seem to be part of the same thing.
Another
explaination for the top-down connections is that they exist to
direct attention. If that is true then at
least one study 5 suggests that attention is not to a
single point, but may be almost as spatially complex as visualization
(which would make sense considering the bandwidth of the top-down
connections). Therefore if attention projects such a detailed image
upon visual cortex, it will serve the same purpose for our goals as
visualization. I am not sure visualization and attention are
separable anyway. Is it possible to imagine something without paying
attention to it? How easy is it to anticipate seeing something
without also imagining it? One is at least an indicator of the other.
Reason
2. Even if sensory backdriving is neither sufficient nor
necessary for visualization, classical conditioning would make it an
almost unavoidable side effect of living:
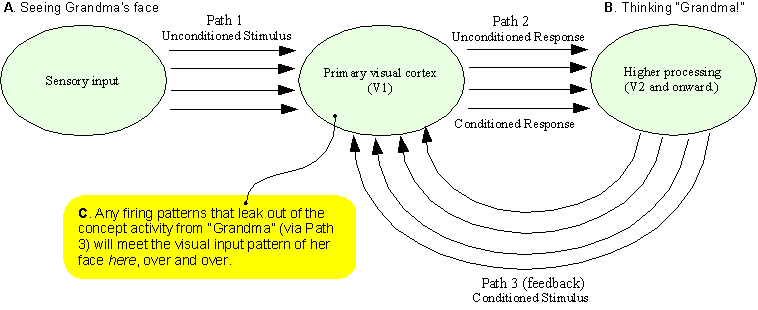
Conditioning
in a Loop
|
|
|
(True,
Grandma's image precedes the concept, but unless Grandma leaves
the room before you recognize her, the concept will also precede
the image.)
Classical
conditioning would describe Path 1 (visual input) as the
Unconditioned Stimulus to V1, and Path 3 (feedback) as the
Conditioned Stimulus, so that after many repetitions, even when
V1 receives no sensory input it will fire in the “Grandma”
visual pattern when it receives “Grandma”
concept-related firing patterns via Path 3.
...And
even assuming the patterns coming down Path 3 contain only
incidental leakage from conceptual activity - if they have any
idiosyncrasies at all unique to the identification of “Grandma”
then they will have a unique association with the sensory image
of Grandma.
|
There
is a lot more that can be said about the backdriving model.
But the point is, if it is accurate, we might very well decode mental
imagery if we can map out internally-generated V1 activity
independently from visual input. On the next page, we'll cover a
possible way to do that non-invasively.
